SIMD - Single Instruction, Multiple Data
Architectures
- Single Instruction Single Data (SISD)
- Single Instruction Multiple Data Streams (SIMD)
- Multiple Instructions Single Data Stream (MISD)
- Multiple Instructions Multiple Data Streams (MIMD)
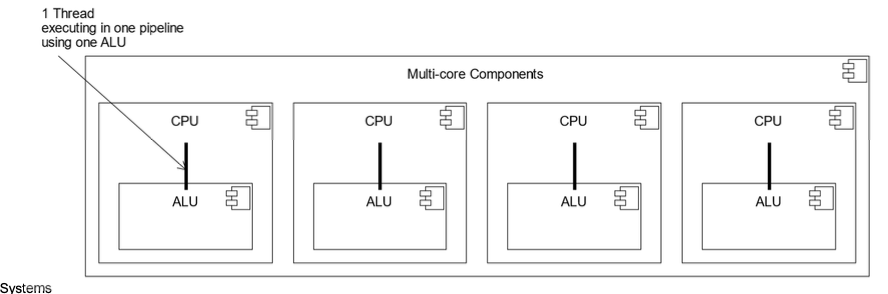
Single Instruction Single Data (SISD)
- Standard general-purpose single-core CPU operation
- Generally associated with a single Functional Unit (ALU)
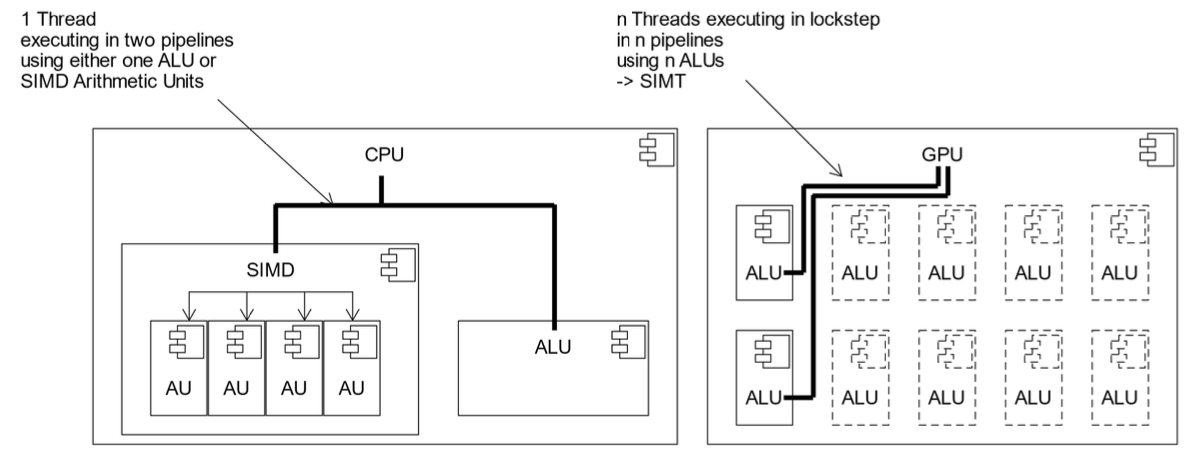
Single Instruction Multiple Data (SIMD)
- A single instruction works on multiple data streams
- Associated with multiple Functional Units (FU)
- Abstracted to Single Instruction Multiple Threads (Nvidia)
- Further abstracted to Single Program Multiple Data (pattern)
Single Program Multiple Data (SPMD)
Running the same programm on multiple UEs
(Multiply-accumulate) MAC Functional Units
- Efficiency in Arithmetic Operations
- Digital Signal Processing (DSP)
- Machine Learning and AI
- Scientific Computing
-> Many algorithms multiply and then accumulate
SIMD Vectorisation Operation
NEON Intrinsics
- allows for efficient parallel processing of data, which can significantly enhance performance for certain types of computations.
https://developer.arm.com/architectures/instruction-sets/intrinsics/#q=

Single Instruction, Multiple Data (SIMD) instructions on ARM NEON (Advanced SIMD) are designed to perform the same operation on multiple data points simultaneously, enhancing performance in multimedia, signal processing, and other applications. Here is a summary of key aspects of SIMD instructions on ARM NEON:
Overview
- SIMD Architecture: NEON operates on vectors, which are groups of elements (8, 16, 32, or 64 bits in size) processed in parallel.
- Registers: NEON has 32 64-bit or 16 128-bit registers, referred to as Q (quad-word) and D (double-word) registers.
Data Types
- Integer: 8-bit, 16-bit, 32-bit, and 64-bit integers.
- Floating Point: 32-bit and 64-bit floating point.
- Fixed Point: Supports fixed-point arithmetic, useful for certain DSP applications.
- Polynomials: Supports polynomial arithmetic operations.
Key Instructions
-
Load/Store Instructions:
- VLDn: Load multiple elements from memory into NEON registers.
- VSTn: Store multiple elements from NEON registers to memory.
-
Arithmetic Instructions:
- VADD: Vector add.
- VSUB: Vector subtract.
- VMUL: Vector multiply.
- VMLS: Vector multiply and subtract.
- VMLA: Vector multiply and accumulate.
-
Comparison Instructions:
- VCGE: Vector compare greater than or equal.
- VCGT: Vector compare greater than.
- VCLE: Vector compare less than or equal.
- VCLT: Vector compare less than.
-
Logical Instructions:
- VAND: Vector bitwise AND.
- VORR: Vector bitwise OR.
- VEOR: Vector bitwise exclusive OR (XOR).
- VBIC: Vector bitwise clear.
-
Shift Instructions:
- VSHR: Vector shift right.
- VSHL: Vector shift left.
- VRSHR: Vector round and shift right.
- VRSHL: Vector round and shift left.
-
Miscellaneous Instructions:
- VABS: Vector absolute.
- VNEG: Vector negate.
- VSQRT: Vector square root.
- VMOV: Vector move (transfer data between registers).
- VDUP: Vector duplicate (replicate a scalar across a vector).
Execution
- Parallelism: Executes operations on multiple data elements in parallel, improving throughput.
- Pipeline: NEON instructions can be pipelined to enhance performance further.
- Optimized Libraries: ARM provides optimized libraries (e.g., ARM Compute Library) leveraging NEON for common tasks.
Use Cases
- Multimedia Processing: Efficient handling of audio, video, and image processing tasks.
- Signal Processing: Enhancements in digital signal processing (DSP) applications.
- Machine Learning: Accelerates inference operations for neural networks and other ML models.
- Games and Graphics: Improves performance in graphics rendering and game physics calculations.
Performance Considerations
- Alignment: Data alignment is crucial for maximizing performance.
- Memory Access Patterns: Optimized memory access patterns can prevent stalls and improve efficiency.
- Instruction Scheduling: Proper instruction scheduling can maximize NEON pipeline utilization.
ARM NEON provides a powerful set of SIMD instructions that significantly enhance the performance of applications requiring parallel data processing. Its comprehensive set of instructions covers a wide range of operations, making it a versatile tool in the ARM architecture.