Patterns
Multiple patterns may be used concurrently.
How to find concurrency?
- Finding a general solution and applying that pattern
- Perform a dependency analysis
- Either progress to algorithm-structure or return to finding a general solution
Finding Concurrency
- Task Decomposition pattern
- Dependency analysis pattern
Algorithm structure
- Task parallelism pattern
Supporting Structure
- Fork / Join pattern
Implemenation mechanism
- Processes & Threads
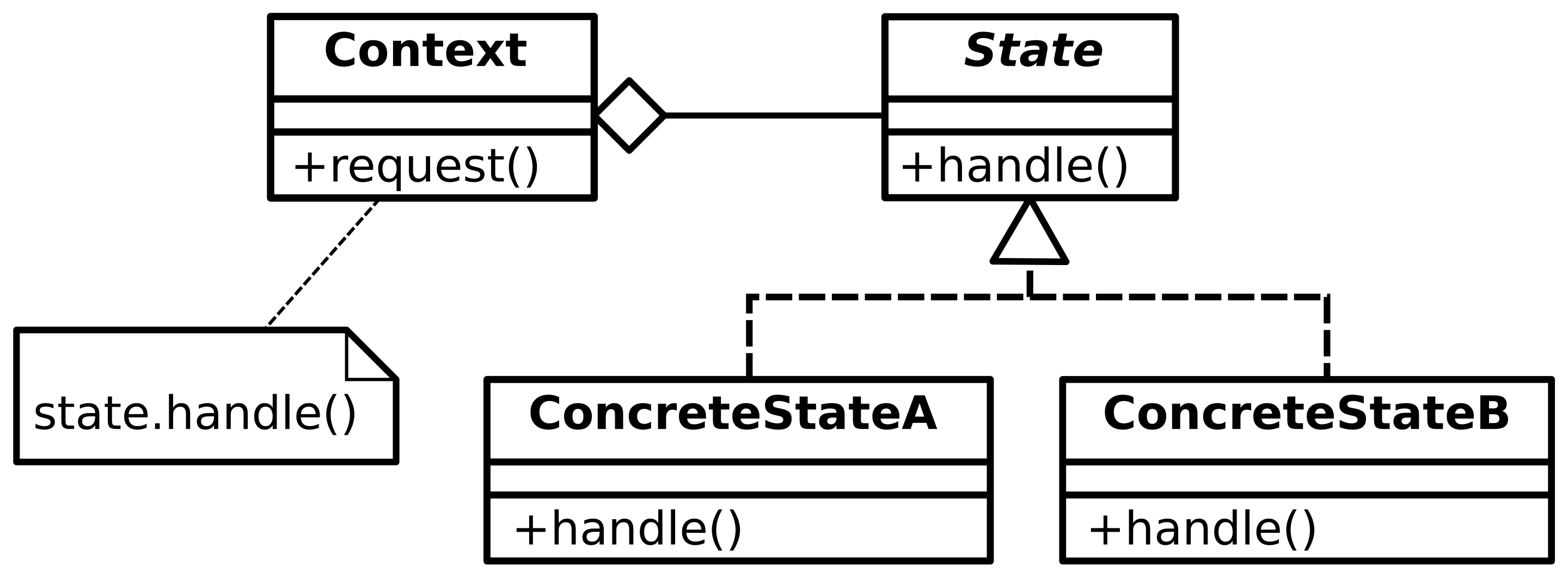
State Pattern
- Allows an object to alter its behavior when its internal state changes
Task Decomposition Pattern
- Decomposes a problem into concurrently executable tasks
- Define the solution space of a task, as independent as possible
- Define the features of said task
Possible solutions
- Functional Decomposition: When splitting the program based on the function
- Loop Splitting: Distinct iterations of a loop
Control Flow Graph
The control flow graph displays all possible execution paths of a program
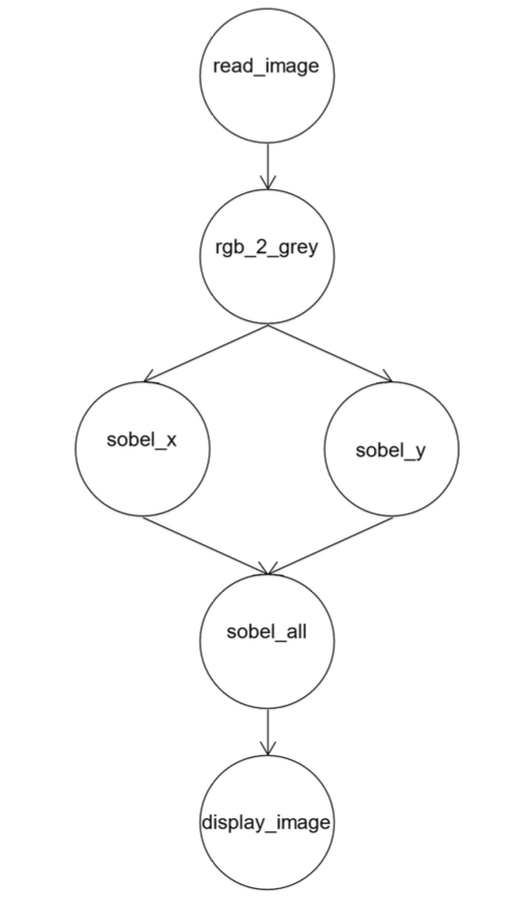
-> Each buble represents a identifiable task
Dependency analysis pattern
Group Task Pattern
- How to group tasks that make up a problem to simplify analysing dependencies
Order Task Pattern
- How must the groups of tasks be ordered to satisfy constrains
Data Sharing Pattern
- How is data shared amongst tasks
Solution
Shared Data can be:
- read only
- effectively-local
- read write
- accumulate
- multiple-read single-write
Task Parallelism pattern
Dependencies
- Order Dependencies must be encored
- Data dependencies
- Removable dependencies - can be removed by code / loop transformation
- seperable dependencies - data strouctrues could be replicated (replicated data)
Schedule
- How are tasks assigned to UEs and how are they scheduled for execution?
Static Scheulde
- Defined a priori
- low management effort but low numebers of tasks
Dynamic schedule
Higher management but for unknown or unpredictable task load
- Define a task queue and when UE completes is current task, it gets a new one from the queue
-> UEs with tasks completed faster will take more from the queue
Work-Stealing: if UE has nothign to do, it looks to the queue of otehr UEs and takes a task to do (adds significant complexity)
Fork / Join Pattern
- Implies the cloning of section of code into another (structurally - but not necessarily in terms of data) independent task
- teh fork-join pattern is NOT an abstraction of the POSIX fork, if anything vice-versa
Use-cases
- recursive structure, such as trees - lend themselves to fork-join
- irregular sets of connected tasks
- where diffeent functions are mapped onto different tasks
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#define NUM_PROCESSES 4
#define ARRAY_SIZE 1000
int array[ARRAY_SIZE];
void sum_array(int start, int end, int* result) {
for (int i = start; i < end; i++) {
*result += array[i];
}
}
int main() {
// Initialize array with values 1 to ARRAY_SIZE
for (int i = 0; i < ARRAY_SIZE; i++) {
array[i] = i + 1;
}
pid_t pids[NUM_PROCESSES];
int partial_sum[NUM_PROCESSES] = {0};
for (int i = 0; i < NUM_PROCESSES; i++) {
pids[i] = fork();
if (pids[i] < 0) {
perror("fork");
exit(EXIT_FAILURE);
} else if (pids[i] == 0) {
int start = i * (ARRAY_SIZE / NUM_PROCESSES);
int end = (i + 1) * (ARRAY_SIZE / NUM_PROCESSES);
sum_array(start, end, &partial_sum[i]);
exit(partial_sum[i]);
}
}
int total_sum = 0;
for (int i = 0; i < NUM_PROCESSES; i++) {
int status;
waitpid(pids[i], &status, 0);
total_sum += WEXITSTATUS(status);
}
printf("Total sum using fork-join: %d\n", total_sum);
return 0;
}
Geometric Decomposition
- Sequence of operations on a core data structure
Solution
- Assign chunks
- Ensure data available for chunks
- Define the updating process for chunks
- Group and map chunks to UEs
Data sharing between chunsk
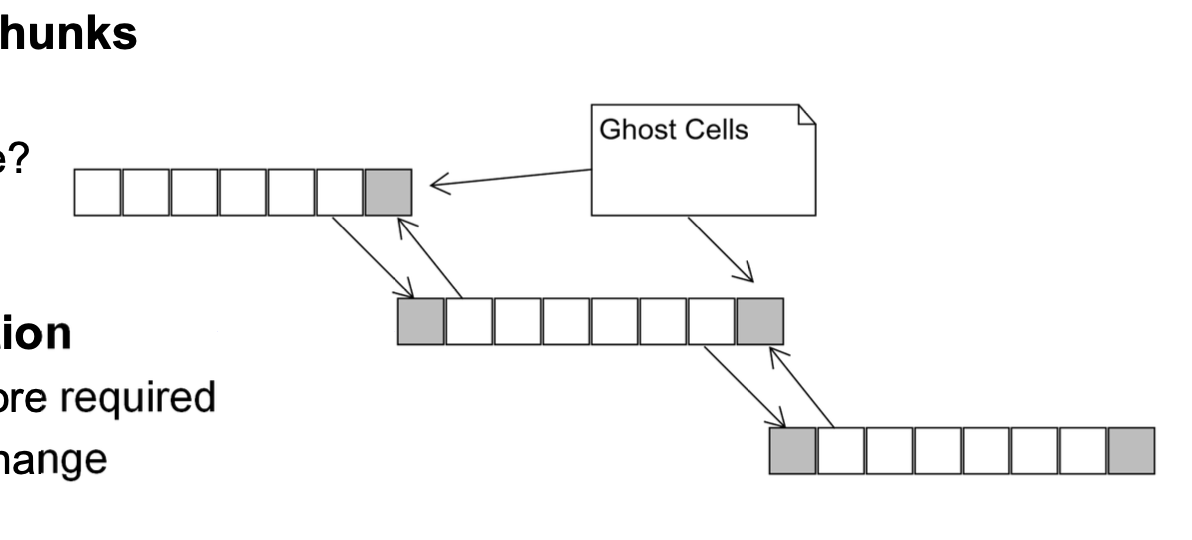
Exchange Options
- (A) A-Priori - perform exchange
- copying or messaging
- updating is straight forward
- (B) Computation and communication overlap
- compute local data whils boundary data is being transmitted
- updating requires multi-threading, communication and computation may work
Loop Parallelism Pattern
Loop parallelism is a technique to speed up programs by running loop iterations at the same time on multiple processors.
Problem
You have a loop in your code that takes a long time to run. How can you make it faster?
Solution
- Check Independence: Ensure each loop iteration can run without waiting for others.
- Parallelize: Use tools (like OpenMP) to split the loop so each part runs on a different processor.
Result: The loop runs faster because multiple processors handle different parts simultaneously.
Benefits
- Speed: Reduces the time needed to run the loop.
- Efficiency: Uses multiple processors effectively.
Considerations
- Complexity: Managing parallel tasks and ensuring no conflicts (race conditions) can be tricky.
- Debugging: Finding and fixing errors is harder in parallel programs.
Use it when: Your program has loops that take a long time and can run independently.
Solution
- Check Independence: Ensure each loop iteration can run without waiting for others.
- Parallelize: Use tools (like OpenMP) to split the loop so each part runs on a different processor.
Distributed Array Pattern
Distributed array is a method for dividing arrays between multiple processors to improve efficiency and performance in parallel computing.
Problem
Large arrays need to be processed efficiently across multiple processors. How can you distribute the array elements effectively?
Solution
- Partition Arrays: Divide the array into blocks that can be distributed among processors.
- Map Blocks to Processors: Assign blocks to processors in a way that balances the load and minimizes communication overhead.
Result: The array elements are processed more efficiently as each processor works on a different part of the array.
Benefits
- Load Balancing: Distributes work evenly among processors.
- Memory Efficiency: Ensures efficient use of memory by aligning array distribution with the flow of computation.
Considerations
- Communication Overhead: Managing data exchange between processors can introduce delays.
- Index Mapping: Aligning local and global indices requires careful management to ensure correct data processing.
Use it when: Your program involves large arrays that need to be processed in parallel, and you want to optimize performance and memory usage.
Single Programm Multiple Data Pattern (SPMD Pattern)
Single Program Multiple Data (SPMD) is a parallel computing model where multiple processors run the same program but on different data.
Problem
Managing interactions between multiple processors running the same program but on different data sets. How can this be organized efficiently?
Solution
- Initialize: Load the same program on all processors and establish communication.
- Unique Identifiers: Each processor gets a unique identifier to differentiate its tasks.
- Distribute Data: Each processor works on its own portion of the data.
Result: The program runs on multiple processors simultaneously, each handling different data, improving overall performance.
Benefits
- Scalability: High scalability as each processor can handle different data independently.
- Maintainability: Easier to maintain a single code base.
Considerations
- Data Distribution: Efficient data distribution and management are crucial.
- Synchronization: Proper synchronization to manage data dependencies and interactions between processors.
Use it when: You need to run the same operations on different data sets across multiple processors for better performance and scalability.
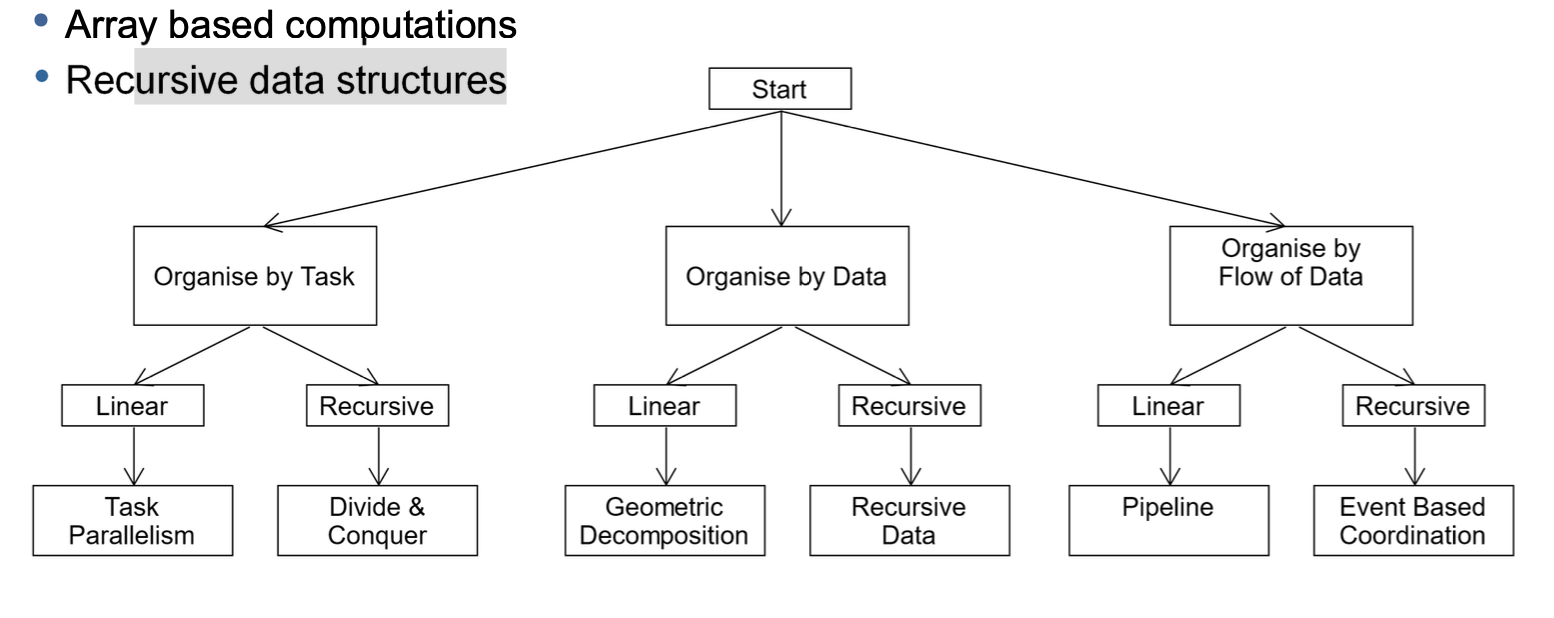
Data Decomposition
-> Organise by data
Flexibility
Granularity Know
-
Defines Chunks whose size and number are parameterizable -> Used for fitting the solution onto different HW • Impact of granularity
-
Overhead of dependency management of chunks versus computational effort - The time managing dependencies must be small wrt computational effort - Boundary cells
- Cells at boundary of chunk -> set size increases with surface area
- Cost = constant overhead + per cell effort
- Computational effort -> scales with volume
- Rough-tune dependency management with computational effort
Efficiency
- Work versus overhead (see above)
- How do chunks map onto UEs
Geometric Decomposition
General Solutions
- Array based computations
- Recursive data structures
Tasks
Distinct
- independently of each other
- do not rely on each other's results & resources during their execution
Dependent
- relies on the results of another task
Processes
- Unit of resource ownership
- Unit of scheduling
- POSIX defined
Definition
- has its own main
- owns resources (memory, file handles, ...)
- is assumed to have exclusive access to all computing and hardware resources 100% of the time
- may be managed by an operating system
- in a multi-process OS, the OS will schedule the processes accoring to some policy
- the memory protection unit (HW) will protecte the integrity of the process' memory from other processes
POSIX Processes
Portable Operating System Interface (POSIX)
- Behavioural specification
- defines how processes and threads are created and terminated
- operating systems may (or may not) suppport POSIX

- Process is created through a fork
- fork clones (total copy) the calling process to child
- child inherits copies of resources
- child/parent variables are handled seperateely (copy on write)
- parent and child run independently of each other
- os scheduled seperately by the OS
POSIX Threads
- Under POSIX, created within a process
- Operates in the context of a process
- Can access all process reosurce including memory
- Kernel management threads -> kernel knows threads exist and schedules them
- default-linux-behaviour
- user-threads -> threading in user space
- kernel does not know of their existence
- user-threads library schedules, not OS scheduler, schedules threads
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#define NUM_THREADS 4
#define ARRAY_SIZE 1000
int array[ARRAY_SIZE];
int partial_sum[NUM_THREADS] = {0};
pthread_t threads[NUM_THREADS];
void* sum_array(void* arg) {
int thread_part = *((int*)arg);
int start = thread_part * (ARRAY_SIZE / NUM_THREADS);
int end = (thread_part + 1) * (ARRAY_SIZE / NUM_THREADS);
for (int i = start; i < end; i++) {
partial_sum[thread_part] += array[i];
}
pthread_exit(0);
}
int main() {
// Initialize array with values 1 to ARRAY_SIZE
for (int i = 0; i < ARRAY_SIZE; i++) {
array[i] = i + 1;
}
int thread_parts[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
thread_parts[i] = i;
pthread_create(&threads[i], NULL, sum_array, &thread_parts[i]);
}
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
int total_sum = 0;
for (int i = 0; i < NUM_THREADS; i++) {
total_sum += partial_sum[i];
}
printf("Total sum using pthreads: %d\n", total_sum);
return 0;
}
UE - Units of Execution
- Creation and destruction of threads are costly
- reuse them as much as possible